 Japan Information
Japan Information Mobile Suit Gundam: Hathaway’s Flash – Witch of Circe (キルケーの魔女)
Hey there, fellow fans of giant robots, dramatic space politics, and all things that make our hearts beat so furiously i...
Japan Information 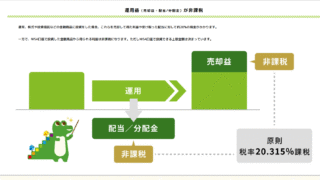 Japan Information
Japan Information  Japan Information
Japan Information  Japan Information
Japan Information  Japan Information
Japan Information  Japan Information
Japan Information  essay
essay  IT
IT  IT
IT  slang
slang